该论文研究的核心问题是:在代码生成任务中,语言模型是否需要先学会“推理链”(Chain-of-Thought, CoT),再去生成代码?
过往对于CoT的研究主要集中在传统逻辑任务,过往研究已经证实使用CoT进行SFT对传统逻辑任务的输出质量有明显提升。但对于CoT在代码生成相关任务中的研究还非常有限。
以往的直觉是:让模型先推理再输出,效果会更好。但作者们发现:这种传统顺序(CoT→输出)在代码生成里未必有效,甚至可能拖后腿。
预备知识
pass@k
核心定义
pass@k一般是在机器学习、特别是代码生成或问答模型里用来衡量模型表现的指标。简而言之,就是对每个问题进行k次尝试,至少成功一次的问题的比例。
基本含义:
给模型一个输入问题,它会生成 k 个候选答案。
如果其中 至少有一个 是正确的,就算作“成功”。
pass@k 就是:在很多测试样本里,成功次数占总样本数的比例。
比如让模型解100道题,每道题模型给出5个解答(k=5),如果这中间有70道题的5个解答至少对了一个,那么
数学上,pass@k的定义如下:
计算方法
由于实际我们无法知道真正的成功率p是多少,因此pass@k的计算有一些技巧。
当p很小(成功率较低,或者说模型在这类问题上能力较弱)时,可以用 kp 来近似计算;
更一般的情况中,我们可以先采样n次,记下正确的个数c,然后采用 \hat{\text{Pass@}k} \;=\; 1 - \frac{\binom{n-c}{k}}{\binom{n}{k}} 进行估计。它是一个无偏估计器。
greedy解码
greedy解码在每一步直接选取概率最大的token作为输出,不做随机采样。最直观的表现是:对于同样的输入,输出结果永远相同。
缺点:可能卡在局部最优,缺少多样性
优点:非常适合评测,模型表现稳定,可复现。
温度
在生成模型中,温度T是一个控制采样随机性的超参数。它在softmax中起作用:
T=1 :原始分布,不做任何缩放
T > 1 :概率被"拉平",模型更发散,更容易出现罕见token,生成更有创造性
T < 1 :概率更"尖锐",模型更保守,偏向于选择概率最大的token
T=0.0 :严格来说是趋近于0,分布退化成只保留最大概率的token,表现上和greedy解码一致,每次的选择都确定。
T=0.0实际上是T趋近于0。此时对于概率最大的token有 P_k = 1 ,对于其他 z_i < z_k ,都有 P_i = 0 。
SFT监督微调
用人工标注的高质量数据来继续训练预训练模型,让模型更贴合特定的任务或风格。
每一条标注数据包括:
输入(prompt):用户的需求
输出(response):理想的输出结果
每一个"输入-输出对"构成了一个人工标注的数据,把它喂给模型后,模型对于当前输入x,根据当前参数 \theta 生成输出序列的概率分布。把预测分布和真实答案y逐token对比,用交叉熵函数衡量当前输出分布和参考答案之间的差距。再经过反向传播等步骤更新参数,达到训练的目的
更通俗地讲,对于每个"输入-输出",模型根据输入给出自己的输出,然后根据交叉熵函数来判断模型这次输出有多接近,据此更新一次模型的参数,循环往复,以此让模型具有解决特定任务的能力。
在该论文中,讨论的重点是SFT数据集的输出中CoT和代码的顺序对训练后模型性能的影响
方法(数据处理)
由于在该论文之前,与代码生成相关的很多开源SFT数据集中大量存在CoT和代码混杂的情况。论文的目标是讨论CoT的作用以及CoT和代码的顺序对训练结果的影响,因此必须清晰地分离输出中的CoT和代码,方便直接对比不同情况下的性能。这一节的重点就是如何构造出CoT和代码分离的、干净的、高质量的数据集。
简而言之,本文采用教师-学生式的上下文蒸馏:
先从开源数据集中筛选任务形式一致,形式类似"编程任务-参考解答"的种子数据集。
再通过一个足够强大的教师模型 M_t 针对种子数据多次生成回答(包括CoT和代码),再从中挑出质量最好的三个示例,放进prompt里作为few-shot示范。随后M_t 会参考这三个示范,为每个种子数据生成推理过程 r_i 和更规范的代码 c_i ,最终得到四元组数据 \{x_i,y_i,r_i,c_i\} 。
让M_t 自行对每个数据生成多个测试用例,只保留能通过测试的代码;同时还要去除CoT与代码不符的数据。确保代码有效且推理对齐(自一致性),自此已得到干净、CoT与代码分离、高质量的SFT数据集。
得到干净数据后,将数据重排对学生模型 M_s 分别做四次微调,进行性能对比。
数据处理方法的流程图如下所示:
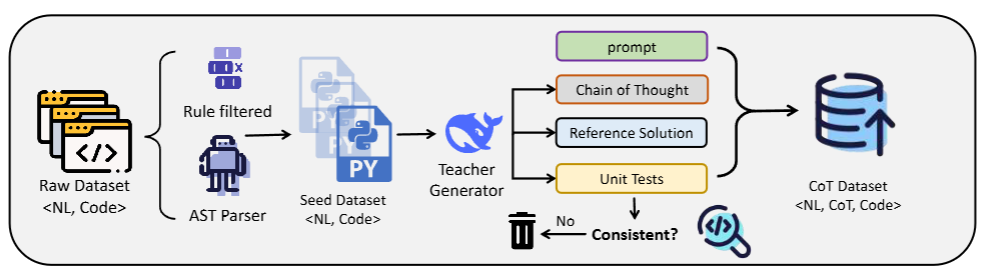
论文附录A:合成数据流程
种子数据源
该论文提到以往代码生成方向的SFT常用GitHub或 Common Crawl 的原始代码段当种子数据。但对于此处的核心问题来说缺点很明显:
论文最终想要做的事情是比较输出中CoT和代码对模型性能的影响,既然是比较而不是实际应用,就需要尽可能保证影响因素更可控,让实验更公平。而直接从GitHub截取的源码片段质量参差不齐;且往往不够具有挑战性和多样性,难以生成高质量的推理和解答。
我个人认为最大的缺点是任务形式不统一,这样对比的结果有太多不可控因素影响了。
所以论文作者从一些编程题数据集中(不是用于SFT的开源数据集)筛选合适的数据作为种子集,种子集中的数据形式都类似于 \{x_i,y_i \} ,其中 x_i 是编程任务(prompt), y_i 是参考解答。这个种子集将作为后续数据构造的few-shot。
数据构造——如何得到高质量且相互分离的CoT和代码?
现有的SFT开源数据集普遍都有一个特点:输出中CoT和代码混杂在一起了,而论文想要对比的正是CoT和代码的顺序对模型性能的影响,因此最好是能有CoT和代码分离的数据集。论文中通过教师-学生式的上下文蒸馏进行SFT:
选用足够强大的DeepSeek-V2.5-1210作为教师模型来构造数据集。具体而言,教师模型 M_t 对种子集中每个编程题目进行多次包含CoT和代码的回答,从中选出3个最合适的作为few-shot示例。
让 M_t 参考few-shot对每个种子数据都生成类似的CoT和代码,快速得到符合要求的数据集。
构造数据的过程中, M_t 同时还会生成多个断言测试,用来自行对CoT和代码进行检测,舍弃不通过的数据,确保代码有效且与CoT对齐。
下面是给 M_t 的prompt模版:

简而言之,就是先让 M_t 对种子数据的问题进行多次回答,挑几个比较好的作为few-shot,再让 M_t 参考few-shot将其他所有种子数据都构造成需要的形式。最后要过一遍测试,去掉明显有问题的代码/推理
对照实验设计——SFT的不同策略
该论文一共设计了四种训练策略,实际上就是将上面得到的数据集进行四种重排后,分别对超参完全一样的模型进行SFT。四种训练策略的数据集中输入都完全一样,但输出有区别:
Seed Dataset:数据为 \{x_i,y_i\},最初始的种子数据集,没有做任何干扰。该数据集构成了训练的基础,可作为baseline。
Code without CoT(Cw/o):数据为 \{x_i,c_i\},输出中仅有代码而没有CoT。用于指示没有CoT时的性能表现。
Code follow CoT(Cfollow):数据为 \{x_i,r_i+c_i\},是大模型生成代码的传统的先生成思维链后生成代码的模式,核心对照组。
Code precede CoT(Cprecede):数据为 \{x_i,c_i+r_i\},与传统方法不同,这里先生成代码再生成思维链,实际上相当于将思维链看作对已生成代码的解释。
Seed是最原始的对照组,Cw/o用于检验没有CoT时的性能表现。而Cfollow和Cprecede是本文的核心对照实验,能直接回答标题的问题,它们的区别仅仅在于交换了数据集的输出中CoT和代码的顺序。
实验部分
实验总体设置
学生模型 M_s 的训练:多数结果基于 DeepSeek-Coder-Base-6.7B,训练 3 个 epoch。优化设定:cosine decay 学习率调度,warm-up 比例 0.1,峰值 1×10−51\times10^{-5}1×10−5,最大序列长度 4096。评测框架用 OpenCodeEval。
主要结果
以下结果都是对应测试集中的平均pass@1。
EvalPlus(HumanEval(+) 与 MBPP(+)):
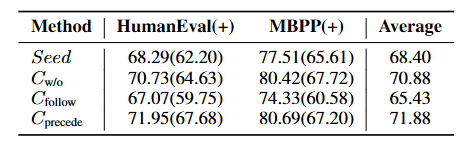
结论是Cprecede明显最好,相对Cfollow有9.86%的提升;并且Cw/o也明显比Cfollow表现更好。LiveCodeBench:
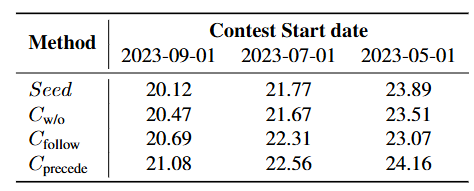
LiveCodeBench强调"无污染"的评测,此处测试了不同起始日期数据下模型的表现。起始日期更新的数据"污染"程度更小,更有可能对模型而言是全新的测试数据。
从测试结果来看,三个起始日期下依旧是Cprecede > Cw/o > Cfollow,一定程度上说明Cprecede的OOD泛化能力同样是最好的
问题:不应该也要观察不同策略下"旧日期和新日期的表现差距"吗?如果Cprecede的绝对能力有碾压优势,无论OOD泛化能力如何,同样会得到类似的结果。BigCodeBench
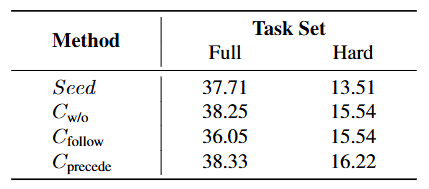
BigCodeBench更强调工具调用和复杂指令处理,该测试能反映更贴近实际应用中的表现。
在Full和Hard两个拆分测试集中,Cprecede仍然最强
实验结果表明:传统的CoT训练方法(Cfollow)在代码生成的任务中表现并不好,测试中甚至还不如完全不用CoT来训练。而先生成代码后生成CoT的策略表现非常好,作者认为这是因为代码本身就是一种推理过程,训练中后续生成的CoT有助于模型更好地理解先前的代码。
传统策略中先生成CoT也更可能导致过度思考。
个人理解:传统任务中的CoT是为了让模型先推理后给出解决方案,但代码生成任务中,"解决方案"是代码,代码本身就是一种推导,就已经有了本来CoT的贡献。而CoT放在代码之后可以帮助模型更好地理解代码。
SFT配置研究(基座模型差异)
本节在EvalPlus上测试了不同基座模型下性能表现,保持超参相同,每100个训练step测一次。
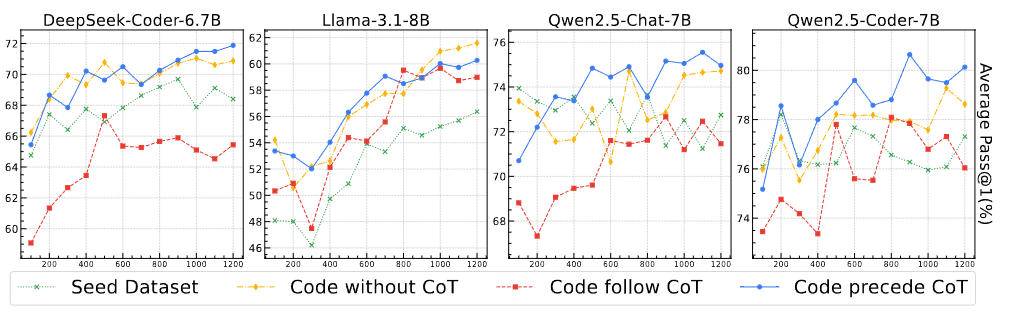
从测试结果来看,不同基座模型的性能差异很大。虽然 SFT 数据与预训练数据有分布差异,大部分情况下Cprecede都是表现最好的策略。这个测试的意图是想说明先Code再CoT的策略在不同基座模型上都是有优势的。
也就是"后生成CoT能够避免过度思考,还能帮助模型更好理解代码"这件事并不是某个基座模型下的特例,在测试的每个模型中都取得了更好的表现。
教师模型研究
作者同样更换了教师模型,以验证在不同教师模型给出的SFT数据集下Cprecede仍然有效
下面是将教师模型更换为GPT-4o-0806后在EvalPlus上的测试结果:
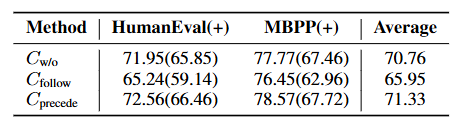
仍然是Cprecede > Cw/o > Cfollow
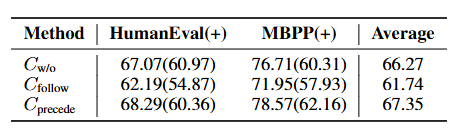
合成顺序研究(教师模型合成数据的顺序)
在第四章节Method中提到,教师模型合成数据的种子数据结构相似 \{x_i,y_i\} , x_i 是任务描述, y_i 是参考解答。为了研究教师模型合成数据的顺序对实验的影响,这个小节的实验强制教师模型必须先生成CoT,并且合成数据不提供参考解答,直接用SelfCodeAlign的教学指令来合成数据(也就是这个实验用的不是此前的种子数据)。
这样可以最大程度避免CoT受到参考解答或可能生成的代码的影响。如果教师模型先看到参考解答再写CoT,可能天然使得Cprecede有优势(避免教师模型照着答案写推理过程)。
于是合成数据中所有的输出都是由教师模型独立完成的,没有其他信息干扰。这个CoT非常的"纯粹",只展现了解决问题的推理过程。
测试结果如下表所示
数据源研究
最简单的一集()
把合成数据的数据源换成Stack重做一遍。Stack是一个包含30多种语言,容量3.1TB的宽松许可源代码数据集。其他训练策略和设置和之前完全一致,测试结果如下:
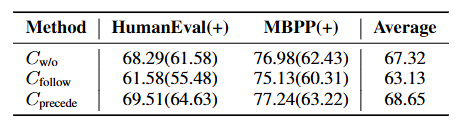
仍然呈现出Cprecede > Cw/o > Cfollow的清晰趋势。说明这个结论对数据域切换也具备可迁移性。
几个实验共同说明了Cprecede策略的优势,先生成代码后生成CoT推理对代码生成的性能表现有明显提升。
讨论
这章围绕四件事展开:1. 为什么把代码放在前、推理(CoT)放在后更有效;2. 训练数据里哪些成分最关键;3. 这些结论在不同规模/难度/设置下是否泛化;4. 两种策略产出的风格差异。
模型行为
为什么Cprecede更有效?
1. 条件困惑度差距:
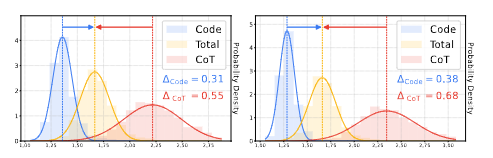
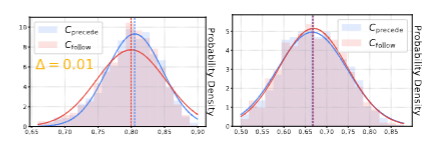
上图分别是Cprecede和Cfollow两种策略下的带高斯拟合的条件PPL(困惑度)分布直方图。
显然,两种策略下都是Code的困惑度更小,说明无论是哪种策略CoT都是更难学习的。作者更关注的是Code和CoT的平均条件PPL和整体的条件PPL(图中黄色的Total)的差距。这个差距可以看出来学习过程是否"平滑、均衡"。
显然左图的差距比右图小一些,这说明Cprecede策略能更好地平衡Code和CoT两个部分的学习。
Cprecede策略中把代码放在CoT前面,代码语法更严谨,token的推断除了靠"猜",很大一部分也依靠严谨的规则。先输出Code很可能可以先行为模型该次学习定好大方向,后续输出CoT的时候就效果更好。如果先输出没有太多规则和标准的CoT,可能会导致过度思考
2. 记忆与泛化
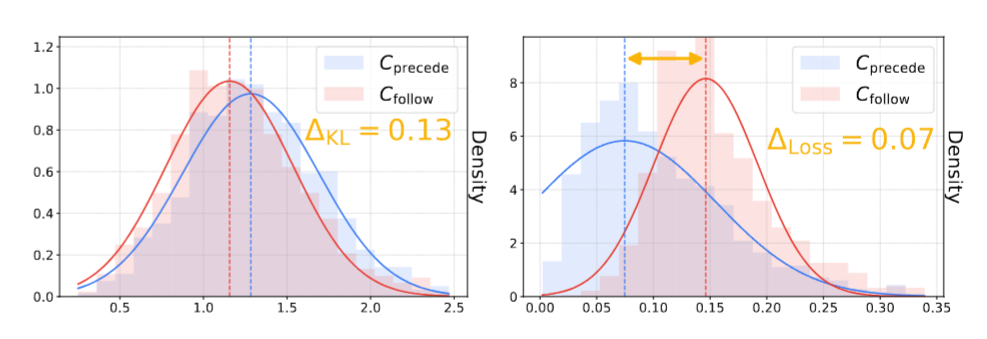
上面左图是两种策略训练前后的KL散度,右图是训练前后的验证损失
两种策略的KL散度分布非常接近,说明二者对基底模型的改动差不多;然而验证损失有显著差距,说明Cprecede的泛化能力明显更优
为什么这里不能用测试集来说明泛化能力,而要看验证损失?GPT说是因为测试集默认只能用一次,用来测试论文的核心问题。这种放在disgussions里的小问题应该都用验证集来测。测试集只留作最终评分,不能反复用来做分析图。验证集则是合法且方便的分析工具。
验证集比起测试集能引入更多不同的数据分布,更好地测试泛化能力,而不仅仅是对模型而言"陌生"。
为什么要测KL散度?如果KL散度差距大,那泛化能力的差距就有可能是因为"Cprecede策略对基模改动更大,使模型整体更适合目标任务",无法充分说明是训练方式本身更好
3. 上下文注意力权重
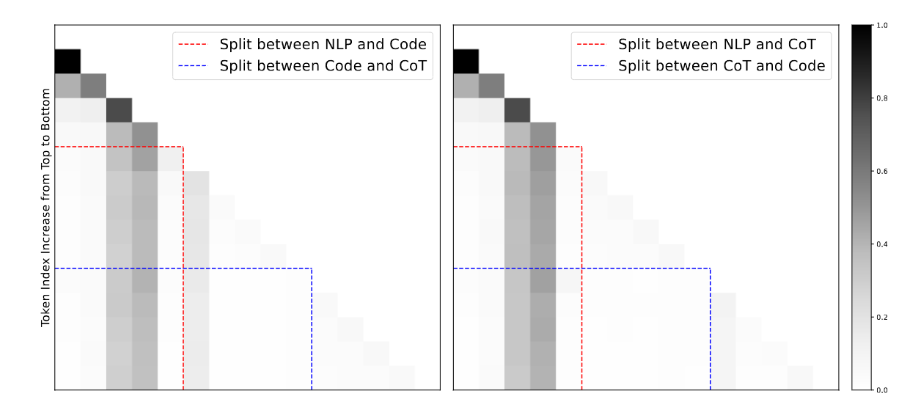
上图中左图表示Cprecede,右图表示Cfollow。横轴表示被关注的token位置,纵轴表示发出注意力的token位置。
在Cfollow策略下,Code对CoT没有特别的注意力偏置,对代码区域的注意力更平均;而在Cprecede策略下,模型会显著加大对Code区域的关注,像是在主动对齐代码与推理的关系。
用 Cfollow 做 SFT 会固化模型对“真实数据分布”的顺序预期(习惯了“先 CoT 再 Code”),从而在遇到不满足这种顺序的输入时产生错配。这会削弱下游任务上的泛化。
这里实际上是通过注意力来进一步解释为什么Cprecede更泛化
4. 层梯度范数分析
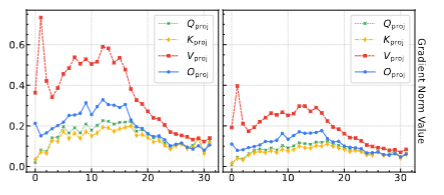
这一节研究训练过程中,不同部分的数据对不同层参数的影响有多大?尤其是注意力相关的投影层(Q_proj, K_proj, V_proj, O_proj)上,梯度的大小和分布是否因为顺序不同而不同。
直接看完整的梯度矩阵难度比较大(矩阵太大了),因此用L2范数来表示每层梯度的整体强度。上图中左图是CoT部分的梯度分布,右图是Code部分的梯度分布。
上图可以看出,首先CoT部分的整体梯度强度比Code部分大很多,说明CoT部分训练时对注意力投影层的影响很大,它推动了模型在较多层数上发生强更新。Code 部分的梯度冲击较小,主要集中在靠前几层,整体影响不如 CoT 那么广泛。
因此Code和CoT的顺序对投影层的梯度影响会非常大。
这里是想额外看看CoT和Code对投影层梯度的作用是否有明显差距。这个小实验是分别单独喂了CoT和Code给模型训练得到的结果。显然结果是Code的作用小很多,对参数更新冲击小。那自然地,改变顺序就会对层梯度产生很大影响。
不同顺序的训练,让这些作用方式和程度都不同的影响以不同的顺序打在了参数上。
数据模式
1. 数据不一致分析和签名/注释移除分析
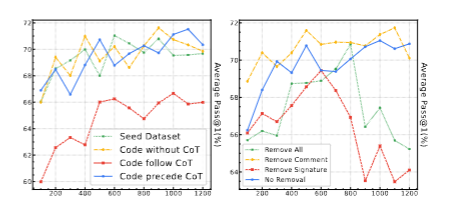
上图是两个研究的实验结果。左图是使用不一致的代码进行训练的模型表现,右图是移除签名/注释进行训练的模型表现。
使用不一致的代码仅会造成微小的性能下降,说明高质量但不完美的代码也对模型学习很有帮助。
移除注释对模型的影响不大,可能是因为代码风格不同;但是移除函数/类签名会导致最显著的性能下降,这说明签名在促进模型学习中有至关重要的作用,推测可能是签名弥合了自然语言和编程语言之间的差距。
2. 两种策略的混合训练分析和对抗性代码训练分析
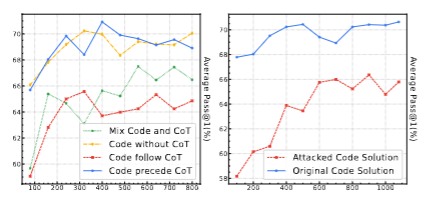
上图左侧展示了混合Cprecede和Cfollow的表现,结果是性能下跌非常多。可能是因为这样会导致同一个问题出现两种答案,让大模型有两种不同的优化目标,反而效果更差了。
上图右侧展示了对抗性代码训练的结果,刻意将代码中的变量名更改为随机的、无意义的字符串,限制模型从词汇中获取信息。结果显示性能明显下跌,这表明模型难以承受对抗性噪声的影响。
泛化分析
1. 跨模型规模泛化
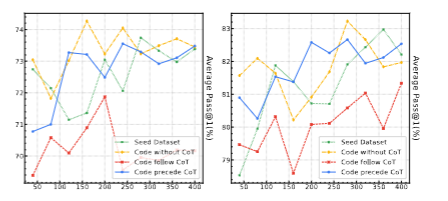
测试大尺寸模型下的能力,通过检测不同规模的底座模型下的表现来验证策略的泛化能力。左侧是DeepSeek-Coder-33B-Base,右侧是Qwen2.5-Coder-32B-Base。结果显示之前的结论仍然成立,说明训练策略具有跨模型规模的泛化能力。
2. 跨难度泛化
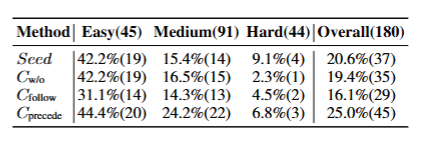
测试Cprecede策略是否能泛化到更有挑战性的问题中。显然之前的结论仍然成立,可以泛化到不同难度的代码任务(Leetcode低中高不同难度)
3. Pass@k与温度泛化
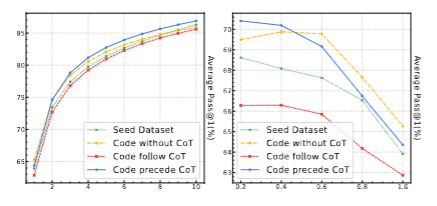
左侧是不同的k值对模型的影响,结果是k值越大,所有策略的表现都显著上升(这很显然,更大的k给了更多尝试机会)。但之前的结论仍然成立,Cprecede仍然是最好的策略
右侧是不同温度对模型的影响,结果是温度越大,所有模型表现都显著下降,并且Cprecede下降最明显。较高的温度会带来更多样但更不精准的结果,Cprecede虽然下滑很明显,但相对性能还是比较稳定,进一步说明了鲁棒性。
输出风格
1. 利用LLM帮助评审偏好
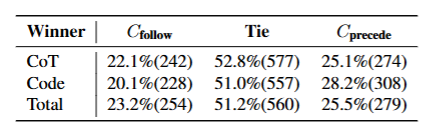
用GPT-4o做评委,让Cprecede和Cfollow分别生成一个答案,让评委模型选出谁更好。并且指出谁的哪一部分更好。为了保证顺序上的公平,每次评审会交换顺序再来一次。
上表可以看出,分不出胜负的情况是最常见的。其他情况中Cprecede明显获胜次数多于Cfollow,说明Cprecede无论是Code还是CoT的生成质量都和现实世界的偏好更接近。
2. 长度和质量的影响
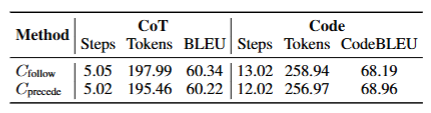
上表对比了两个模型的CodeBLEU分数,来衡量他们生成的代码与参考答案的接近程度。两个模型的分数都很接近,但是Cprecede花费更少的步骤和输出token。也就是为了达到同样的效果,Cprecede的推理开销更少。
3. 输出和指令的匹配程度
计算两种策略下指令(任务描述)和代码、CoT的语义相似程度。
将指令、代码、CoT都用text-embedding-3-large转换成向量表示,然后计算向量间的余弦相似度,用来衡量输出结果与指令之间的一致性和连贯性。左侧是指令与代码的相似度,右侧是指令与CoT的相似度
结论
本论文研究了在SFT中融入思维链(CoT)对大模型代码生成能力的影响。作者们构建了高质量数据集,展开了全面实验。
研究表明,高质量的代码本身就能充当推理过程,而传统的CoT应该被视作对代码的解释,因此代码在前CoT在后的Cprecede策略在各项实验中均有突出的表现。而参考传统逻辑任务的习惯的Cfollow策略甚至还不如不加入CoT的表现。此外,作者们还深入研究了策略的泛化能力、数据模式的影响、模型行为等等,全面说明了Cprecede策略的有效性。