引题:leetcode704 二分查找
给定一个长度为n且有序的(升序)整型数组nums 和一个目标值target ,写一个函数搜索nums中的target,如果目标值存在返回下标,否则返回-1。
整数二分查找的第一种理解:搜索
对于大多数人第一次学习整数二分时,我们学到的理解方式是:通过两个指针low 和high ,从序列nums的两端向中间遍历。由于序列有序,因此low和high初始一定是序列的两个最值点。随后令mid = (low + high)/2,不断检验nums[mid]与目标元素target的关系:如果nums[mid]>target ,则应将high 移动到mid-1 ,反之则将low 移动到mid+1 。
这种思路实际上是通过不断搜索low和high的中间元素,观察其是否为目标元素,并使其尽可能与目标元素位置更近的过程。
下面是上述思路的代码实现:
int search(vector<int>& nums, int target) {
int low = 0;
int high = nums.size() - 1; // 定义target在左闭右闭的区间里,[low, high]
while (low<= high) { // 当low==high,区间[low, high]依然有效,所以用 <=
int mid = low + ((high - low) / 2);// 防止溢出 等同于(low+ high)/2
if (nums[mid] > target) {
high= mid - 1; // target 在左区间,所以[low, mid- 1]
} else if (nums[mid] < target) {
low= mid + 1; // target 在右区间,所以[mid + 1, high]
} else { // nums[mid] == target
return mid; // 数组中找到目标值,直接返回下标
}
}
// 未找到目标值
return -1;
}上述思路看似简单,但对于初学者常常"一看就会,一写就废"。整数二分查找思路上非常简单,但是写代码时一些边界条件并不容易一次写对。通常是虽然最后都能写出来,但总需要经历一系列烦人的debug过程,试出正确的边界条件。
比如上述代码中,while的条件是left < right还是left <= right?更新low和high指针时,是low = mid + 1还是low = mid?这些边界条件实际上对于不同的问题处理起来都不一样。对于没写过几道题的初学者来说是很恼人的问题。 那么是否存在一种对于任何情况都能快速分析这些边界条件的方法呢?
第二种理解角度:区间染色
第一种角度是从二分最原始的思路出发,很直观便于理解,但实现时的各类边界条件并没有在思路上体现,所以写代码时会觉得它们很抽象不好确定。而第二种角度从代码实现出发,每个边界条件背后的意义都很明显:
二分查找实际上就是将序列划分为以目标元素target为边界的两个区间的过程。假设我们将target本身归于右区间,那么左区间的所有元素都应该小于target,右区间所有元素都应该大于等于target。
因此,我们可以将low和high看作左右区间的边界指针,low及其左边的所有元素都应归于左区间,high及其右边所有元素应归于右区间。为了方便理解和描述,这里将low及其左边所有元素标记为蓝色,high及其右边所有元素标记为红色,而尚未处理的,位于low和high之间的元素标记为白色。
下面以nums=[1,2,4,5,8,10,11],target=8为例演示初始状态:
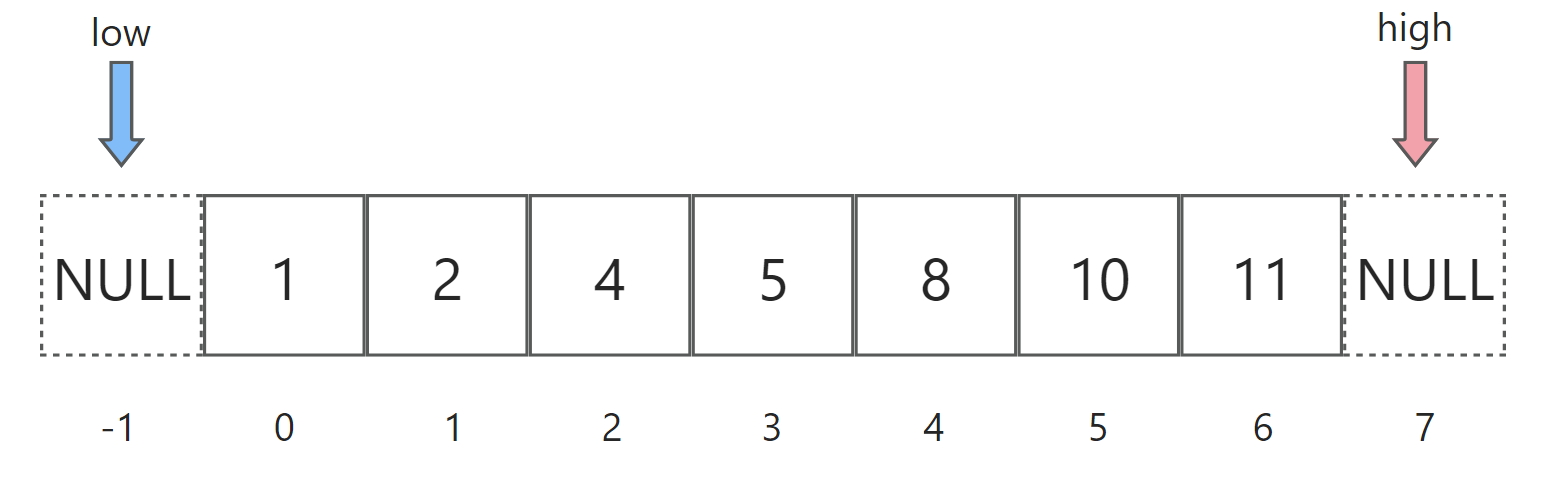
首先计算mid = (low+high)/2,此时等于3。于是nums[mid]=5,小于target,应落入蓝色区间(左区间)。还记得上面说过,low及其左边的所有元素都小于等于target,应标记为蓝色吗?所以此处nums[mid]就是我们目前所知的蓝色区间的最右边界,因此要令low = mid:
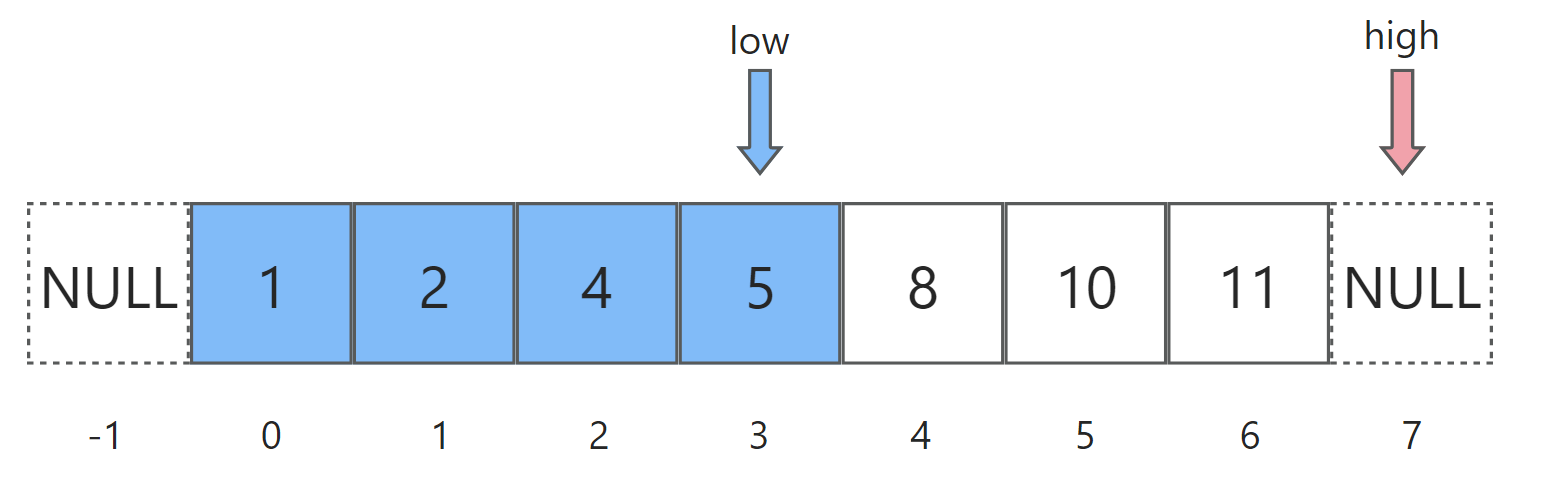
随后开始第二轮循环,继续计算mid = (low+high)/2,此时等于5。于是nums[mid]=10,大于等于target,应落入红色区间(右区间)。此时nums[mid]是目前所知的红色区间的最左边界,因此令high = mid:
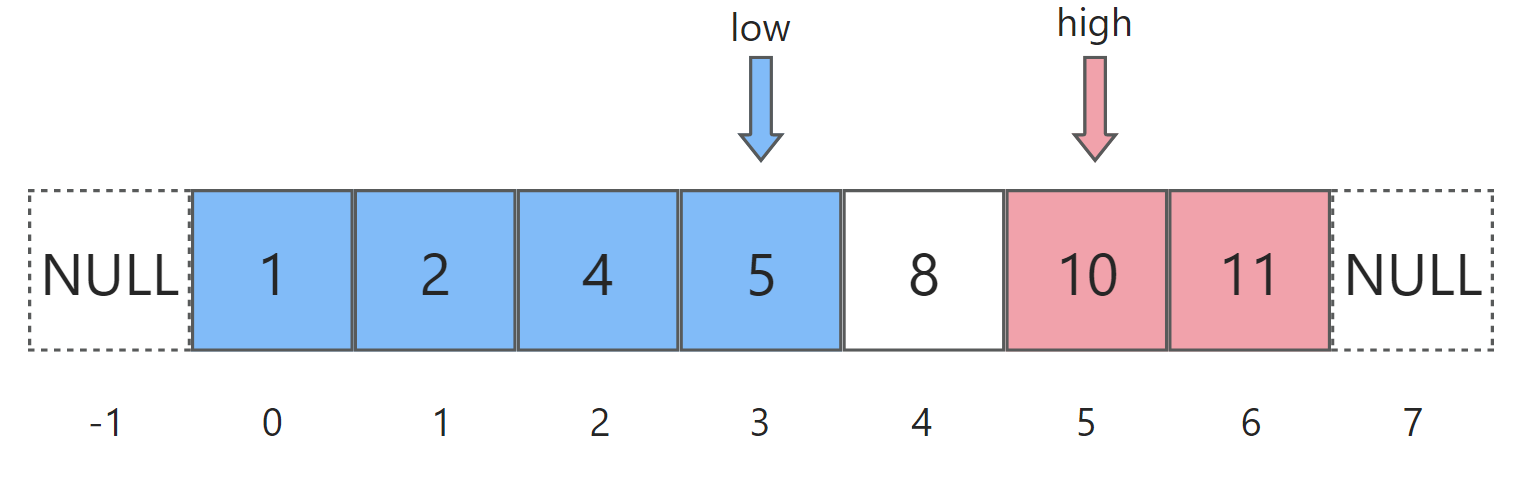
随后开始第三轮循环,mid = (low+high)/2,此时等于4。于是nums[mid]=8,大于等于target,应落入红色区间。此时nums[mid]是目前所知的红色区间的最左边界,因此令high = mid:
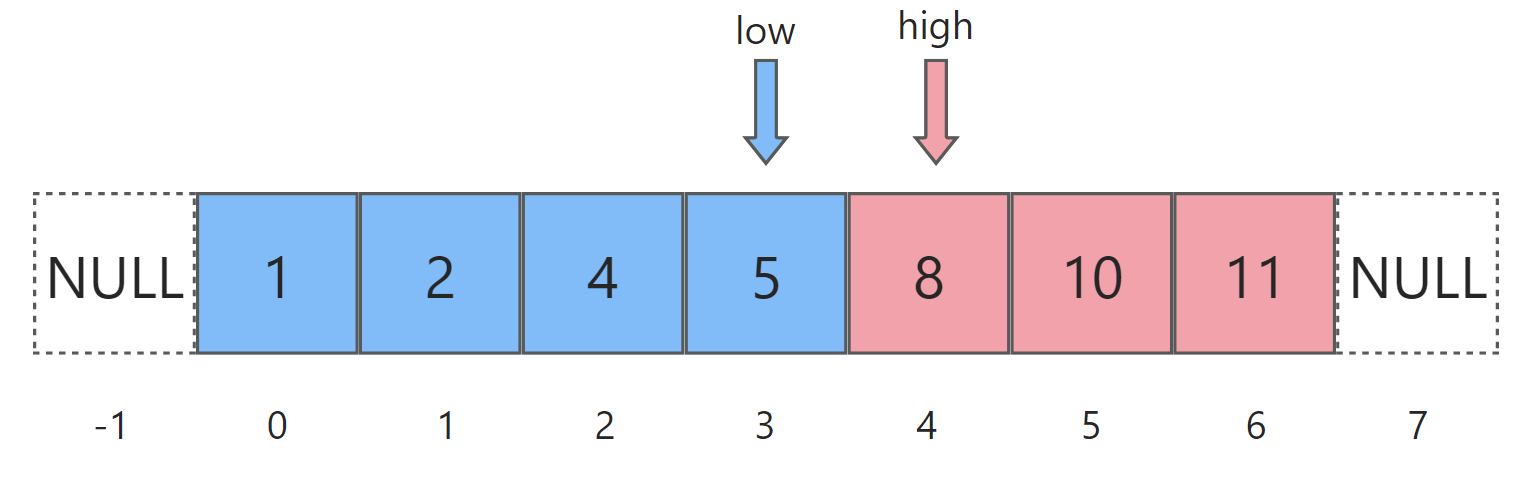
至此,整个序列已经没有白色的元素了,于是二分完成。上述过程将二分查找看作将数组所有白色元素"染色"的过程,而无论在任何二分问题中,对序列的染色过程最终一定是上图所示的情况,此时low与high刚好相邻,分别作为蓝色区间和红色区间的边界。所以while循环的条件应为while(low + 1 < high),代表着此时low和high之间还存在未染色的白色元素。
在不同的问题中,获取答案的方法也不同,而我们只需要记住最终状态是上面这张图,我们就能轻易推出答案的位置。比如这个例子中,target的下标就是high,因为我们规定了target本身应包含在红色区间内。(当然也可以规定成target包含在蓝色区间)
下面给出上述思路的示例代码:
int search(vector<int>& nums, int target) {
int low = -1; int high = nums.size();//初始化low和high
while (low + 1 < high) { //循环条件:low和high不直接相邻,即它们之间还存在未染色的元素
int mid = low + ((high - low) / 2);// 防止溢出 等同于(low+ high)/2
//nums[mid]小于target,落在蓝色区间
if (nums[mid] < target) {
low = mid;
}
//nums[mid]大于等于target,落在红色区间
if(nums[mid] >= target){
high = mid;
}
}
if (high == nums.size() || nums[high] != target) { //若nums[high]不等于target说明查找失败
return -1;
} else {
return high;
}
}该思路来自B站二分查找为什么总是写错?初见这个思路时拍案叫绝,用这个分析方法去做不同要求的二分题,能更直接地感受到它的清晰。