kernel的并行方式
最简单的例子
首先来看一个最经典的场景:向量加法:
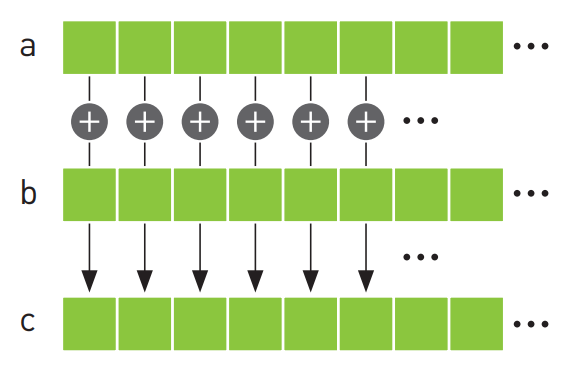
对于向量a和向量b,假如我们想得到它们相加的结果c,在CPU(传统cpp)上,我们只能循环遍历每一个元素,比如:
for(int i = 0; i < a.size(); i++){
c[i] = a[i] + b[i];
}时间复杂度O(n)。但在cuda中,我们可以用如下kernel完成这件事:
#define N 10
__global__ void add(int* a, int* b, int* c){
int tid = blockIdx.x;
if(tid < N){
c[tid] = a[tid] + b[tid];
}
}
int main(){
int a[N], b[N], c[N];
int *dev_a, *dev_b, *dev_c;
//分配显存
cudaMalloc( (void**)&dev_a, N * sizeof(int) );
cudaMalloc( (void**)&dev_b, N * sizeof(int) );
cudaMalloc( (void**)&dev_c, N * sizeof(int) );
//假设a和b中已经被输入数据
//将cpu中的数据复制到GPU指针中
cudaMemcpy(dev_a,a,N*sizeof(int),cudaMemcpyHostToDevice);
cudaMemcpy(dev_b,b,N*sizeof(int),cudaMemcpyHostToDevice);
// 调用kernel进行并行加法
add<<<N,1>>>( dev_a, dev_b, dev_c );
//将GPU数据复制回CPU
cudaMemcpy(c,dev_c,N*sizeof(int),cudaMemcpyDeviceToHost);
cudaFree( dev_a );
cudaFree( dev_b );
cudaFree( dev_c );
return 0;
}上面用__global__声明了一个kernel,然后在main()里面调用它来进行并行加法。和之前不一样的是,这次调用时指定了尖括号里的参数
先看最简单的例子:调用时指定为<<<N,1>>>,意味着指定有N个block,每个block有1个thread。于是下面的代码中:
__global__ void add(int* a, int* b, int* c){
int tid = blockIdx.x;
if(tid < N){
c[tid] = a[tid] + b[tid];
}
}cuda runtime会启动N*1个thread,tid获取的是当前Block编号,在这里实际上也就是thread编号。运行时,cuda runtime会创建N个kernel副本,让N线程分别处理N次加法。这样就实现了并行加法
尖括号中的第二个参数
尖括号中的参数分别是<<<block,threads>>>,用来指定kernel的执行方式。比如<<<3,4>>>,就指定了3个block,每个block中有4个thread。thread是并行的最小单位,block是thread的组织方式。一般来说,一个block所包含的thread数量最好是32的整数倍。
为了更好理解threads的作用,这里稍微改一下:
__global__ void add(int* a, int* b, int* c){
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if(tid < N){
c[tid] = a[tid] + b[tid];
}
}假设我们调用的方式是add<<<2,N/2>>>,这样实际运行时就是前N/2个threads(第1个block)处理前一半的数据,后N/2个threads(第2个block)处理后一半数据。后面应该会接触到更多划分线程组织结构的应用
二维block
我们可以通过如下方式指定二维的grid,使得block之间以二维的方式排布:
dim3 grid(10,10);
kernel<<<grid,1>>>();在kernel中用如下方式获得index:
int x = blockIdx.x;
int y = blockIdx.y;这只是语法上的区别,实际运行中和一维一模一样。我们通常把这种block的集合称为grid。它可以方便在一些多维场景下(比如图像处理)更方便地指定block和threads
device函数
在函数前加上__device__即可声明一个device函数。device函数只能被kernel函数或者其他device函数调用,方便在cuda端做函数封装。多个kernel副本调用它们时,它们也会被并行执行,很方便。
绘制julia set
下面是一个有趣的小实践,通过这个问题来感受一下cuda编程的思路。对于复平面上的一个特定点做如下迭代:
如果它最终收敛,那这个点就按特定的规则着色;如果发散,就不着色(或者按另一个规则着色)
一个点的计算看起来很简单,但如果对范围内所有点都进行这种计算,计算量就会特别大。这个问题有个很显然的特点:每个点之间的计算是不互相依赖的,那就可以用cuda通过并行计算节省大量时间。
思路
绘制julia set中,最大的计算量就在计算每个点是否收敛上,因此这部分肯定需要在device中完成。如果暂时不考虑block和thread的分配问题,可以先简单地让一个点对应一个block。那kernel的任务就是计算某一个特定的点是否收敛,这个点的坐标要和block编号绑定。
在device端完成的所有计算都是并行的,那肯定需要一个公共的内存来统一存放所有计算结果;并且为了写入文件,CPU端也需要一个一样大小的内存,用于接收结果。
是否收敛的计算对于每个点都是一样的,为了代码简洁,首先想到的就是cuda函数是否能有多个?能不能写一个cuda函数专门用来计算是否收敛,给kernel调用?
由于是复平面上的计算,需要封装一个复数类,但是前面说过device函数不能调用CPU函数,那怎么写一个device函数使用的类,又怎么分文件写呢?
理清上面的思路后,我们一个个来解决
数据结构
CPUBitmap类(二维到一维的映射)
我们需要一个连续的数据结构用来在CPU端接收device的结果,这样方便接收cuda端的数据:
// cpu_bitmap.h
#pragma once
#include <cstdio>
#include <cstring>
#include <iostream>
class CPUBitmap {
public:
CPUBitmap(int w, int h)
: width(w)
, height(h)
{
pixels = new unsigned char[image_size()];
std::memset(pixels, 0, image_size());
}
~CPUBitmap()
{
delete[] pixels;
}
// 返回pixels的指针
unsigned char* get_ptr()
{
return pixels;
}
int image_size()
{
return width * height * 4;
}
// 写为PPM
void display_and_exit(const char* filename = "julia.ppm")
{
FILE* f = std::fopen(filename, "wb");
// f创建失败
if (!f) {
return;
}
// PPM固定开头
std::fprintf(f, "P6\n%d %d\n255\n", width, height);
for (int y = 0; y < height; y++) {
for (int x = 0; x < width; x++) {
// offset正常走(4B一跳),但是下面只取3个,就能跳过alpha
// PPM只支持RGB
int offset = (x + y * width) * 4;
unsigned char rgb[3] = {
// +1就是一个byte,每个byte能表示0-255,对应RGBA
pixels[offset + 0],
pixels[offset + 1],
pixels[offset + 2]
};
std::fwrite(rgb, 1, 3, f);
}
}
std::fclose(f);
}
private:
int width = 0;
int height = 0;
unsigned char* pixels = NULL;
};每个像素的颜色由RGBA决定,RGBA每个范围都是0-255,每个都需要一字节,于是每个像素都需要4B来存储。为了操作方便(方便区分四个字节以及cuda端memcpy),pixels指定为unsigned char*,每个数据1B,4个数据表示一个像素。
这里是用一维char数组表示4B为单位的二维图像,因此需要用:
int offset = (x + y * width) * 4;进行映射,把x + y width想象成一行一行跳着走的过程即可,乘4是因为4B为单位,要四个四个地跳。
unsigned char rgb[3] = {
// +1就是一个byte,每个byte能表示0-255,对应RGBA
pixels[offset + 0],
pixels[offset + 1],
pixels[offset + 2]
};取每个单位的前三个字节,分别为RGB值。然后写入PPM即可。这里使用PPM作为输出形式,因为这个最方便,但是PPM只支持RGB,所以后面要注意跳过RGBA中第四个字节。
cuComplex类(定义device端可以使用的类成员函数)
前缀cu表示这是用于cuda的类,如果正常写的话,里面的函数就都是CPU函数,device端不能用。下面展示了如何写一个device端能直接用的类:
// cuda_complex.h
// 防止IDE误以为这是cpp类而报错
#ifdef __CUDACC__
#define HD __host__ __device__
#define D __device__
#else
#define HD
#define D
#endif
class cuComplex{
public:
float r,i;
D cuComplex(float a, float b): r(a),i(b){}
D float magnitude2(void){
return r*r+i*i;
}
D cuComplex operator*(const cuComplex& a){
return cuComplex(r*a.r - i*a.i, i*a.r + r*a.i);
}
D cuComplex operator+(const cuComplex& a){
return cuComplex(r + a.r, i + a.i);
}
};只需要在所有方法前加上__device__标识符,即可声明类成员函数为device函数,就能在cuda侧被调用。
cuComplex类被写在cuda_complex.h中,只需要在.cu中直接include这个头文件就能使用里面的device函数。
并行计算部分
计算是否收敛
其实这部分很简单,对每个点都迭代200次,看最终会不会超过一个阈值(此处取1000)即可。唯一要注意的是要声明为device函数,因为要被kernel调用:
__device__ int julia(int x, int y){
const float scale = 1.5;
// 相当于平移再归一化
float jx = scale * (float) (x-DIM/2)/(DIM/2);
float jy = scale * (float) (y-DIM/2)/(DIM/2);
cuComplex c(-0.8,0.156);
cuComplex p(jx,jy);
// 迭代200次, 超过1000视为不收敛
for(int i = 0; i < 200; i++){
p = p*p + c;
if(p.magnitude2() > 1000){
return 0;
}
}
return 1;
}对坐标的处理是为了让[0,DIM]映射到[-1,1],方便计算是否收敛,要是不这样做,数值规模无法预料,阈值就不好取
kernel并行(二维grid的使用)
// 每个点都启用一个kernel
__global__ void kernel(unsigned char * bitmap) {
int x = blockIdx.x;
int y = blockIdx.y;
// gridDim保存了grid的形状,此处gridDim == (DIM,DIM)
int offset = (x + y * gridDim.x)*4;
bitmap[offset + 0] = 255 * julia(x,y);
bitmap[offset + 1] = 0;
bitmap[offset + 2] = 0;
bitmap[offset + 3] = 255;
}这里就看出来二维grid的优越性了,grid是二维的,它和图像完美对应上
但这并不是实际应用的写法,这里调用的方式是kernel<<<(DIM,DIM),1>>>,但实际中一般会有效率更好的block和thread数量组合,这个之后在认真研究一下
main函数(cuda编程中的数据交换)
最后通过如下main函数执行:
int main( void ){
unsigned char* cuda_bitmap;
CPUBitmap cpu_bitmap(DIM,DIM);
cudaMalloc(&cuda_bitmap,DIM*DIM*4*sizeof(unsigned char));
dim3 grid(DIM,DIM);
kernel<<<grid,1>>>(cuda_bitmap);
cudaMemcpy(cpu_bitmap.get_ptr(),cuda_bitmap,cpu_bitmap.image_size(),cudaMemcpyDeviceToHost);
cpu_bitmap.display_and_exit();
cudaFree(cuda_bitmap);
return 0;
}上面的执行过程展现了最简单的cuda编程方法,GPU分配所需的显存指针,CPU提供一个同样大小接收数据的缓冲区指针。GPU计算好后,结果自然就在显存指针中,然后通过cudaMemcpy将显存指针的数据赋值给CPU缓冲区,最后CPU端消费这个数据