本章主要学习有关cuda中Block与Thread的关系,Thread间如何通信,以及Thread的同步问题。初步认识cuda如何解决大规模并行问题
CUDA执行层次结构:Grid、Block和Thread
下图表示了Grid,Block,Thread三种结构的递进关系,能俯瞰它们是如何协作处理任务的。
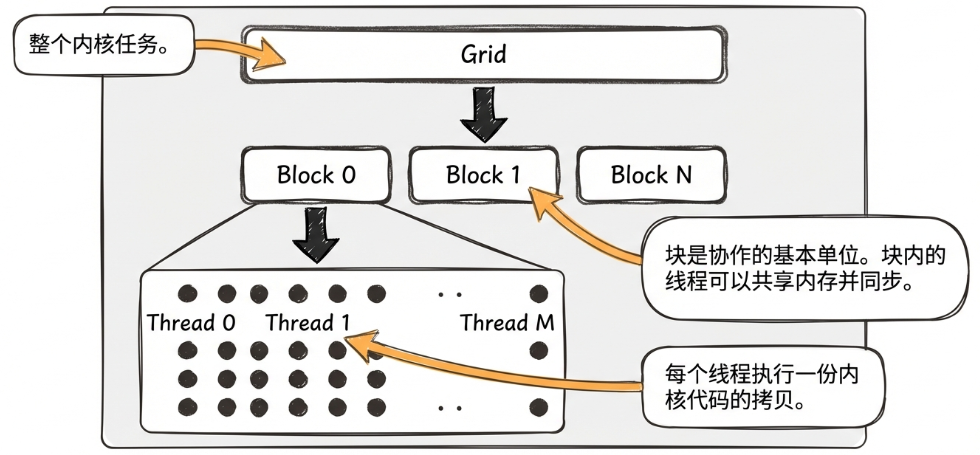
Grid是我们用来表示Block排布方式的结构,比如如下代码:
dim3 grid(10,10);
dim3 block(16,16);
kernel<<<grid,block>>>(data_ptr);上面的代码中定义了10x10=100个block,每个block都有16x16=256个thread。gird结构如何定义不影响实际的计算过程,但block结构会有性能上的区别。
block大小(一个block有多少线程)一般会取128、256、512这几个档。不能超过1024。
blockDim.x比较特殊,x是"变化最快"的维度。因此blockDim.x必须是warp(32个thread)的倍数。
如何处理大规模数据?
首先认识到一个前提:同一个Block内的线程拥有更强的协作能力,比如内存共享,线程同步,资源切换等。
所以最好的情况是用尽可能少的Block,这样更多的线程在同一块内,效率更高。但是一个Block中能包含的Thread数量是有上限的,这就引出了下面这张图:
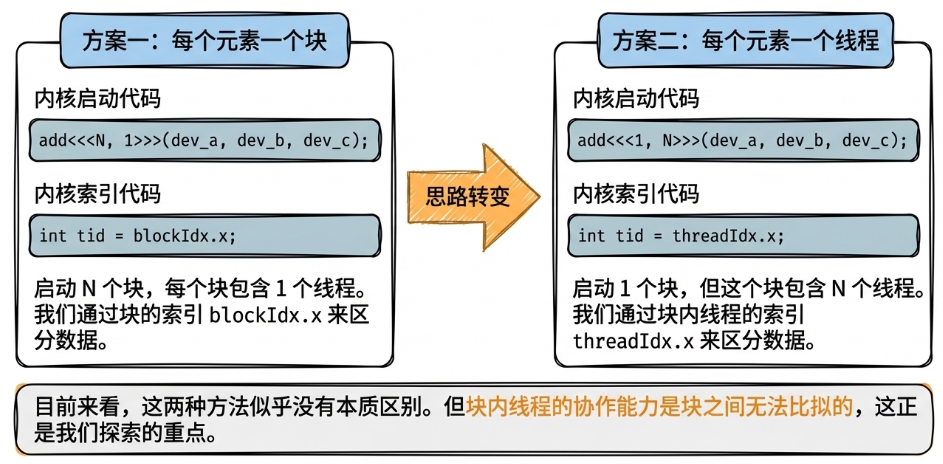
因此我们需要将图中的两种方案混合起来。具体实现中由于gridDim.x的限制,有下面两种情况:
未触发gridDim上限的基础情况
假设我们要进行长度为3*512+100 = 1636的向量并行加法。假设block大小为512,我们如何算出需要的block数量,又如何将线程与向量元素对应起来呢?
下面的代码是一个简单的示例:
// (N+511)/512实际上就是对N/512向上取整。
// 因为我们可以接受多的一个block中有thread被浪费,但不能接受thread不够用
// 多创建的thread可以通过tid < N来排除掉
kernel<<<(N+511)/512,512>>>(...)
__global__ void kernel(...){
// 可以理解为: blockIdx.x * blockDim.x将起点从0偏移到了当前block的起点位置,然后再往后数threadIdx.x就是线程的全局索引
// 此时线程全局索引tid可以对应要处理的向量元素,比如tid = 5就是5号元素
int tid = blockIdx.x * blockDim.x + threadIdx.x;
// 防止tid越界,这样只会有3*512+100个thread被用到,剩下的412个被丢弃不用
if(tid < N){...}
}这个例子比较简单,重点是结合(N+511)/512取整与越界检查来将thread与被操作的元素对应。
数据量太多,没办法完全并行怎么办?
由于gridDim有上限(gridDim.x < 65535),我们不能无限制地创建Block。如果超过上限也无法并行处理全部数据怎么办?
方案之一就是Grid-Stride循环:让每个线程处理完自己的任务空闲后,去做后面可能存在的别的任务。具体如下图所示:
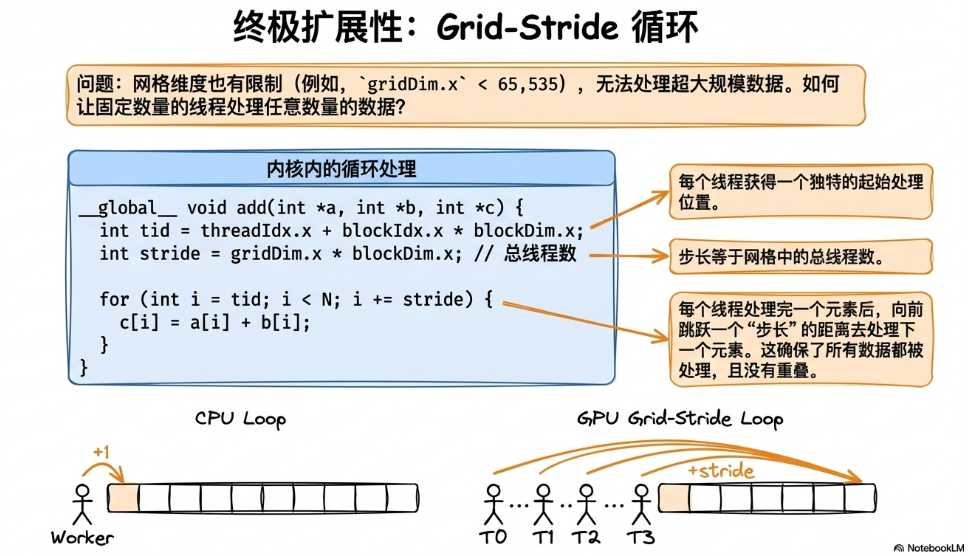
比如上面的基础情况中,假如我们只用了2个Block(一共1024个线程),当tid = 512的线程计算完第512个元素后,它会紧接着去计算第512+1024个元素。跳着将所有元素分配给更少的线程。
Global Memory 与 Shared Memory
Global Memory
Global Memory 是 GPU 上容量最大、所有线程都可以访问的主存。我们通过cudaMalloc分配的内存就是Global Memory。
它的特点是:
容量大,GB级。
所有线程都能访问,包括不同Block的线程。
速度较慢,延迟通常在上百个 cycle。
生命周期跨 kernel/线程,直到释放为止。
使用方式就是简单的cudaMalloc,通过cudaMemcpy赋值。需要程序员手动管理内存(比如cudaFree)。
访问方式会影响性能!主要和warp,Threads访问时与内存的对应方式等有关,后面记得查一下。
Shared Memory
Shared Memory(共享内存)是位于每个 SM 上的一小块高速可编程缓存,供同一个 block 的所有线程共同访问。可以理解成“一个 block 内所有线程共同使用的超高速临时缓存池”。
它的特点是:
速度非常快(延迟接近寄存器,比 global memory 快几十倍到上百倍)。
同一个block内的所有线程都能读写同一片空间,但只在同一个block内共享。
生命周期在 block 级别(block 结束它就被释放)
由于Shared Memory高带宽低延迟,支持并行访问,更利于线程协作计算等特点,一般在矩阵乘法、卷积、稠密计算等操作中,会把小块数据(tile)拷贝进 shared memory,让所有线程重复使用这份缓存,从而加速。
Shared memory 被分成多个 bank(通常 32 个,为什么是32个?)。如果多个线程访问落在同一个 bank,则会发生冲突,速度会变慢。设计访问模式时要尽量做到让 warp 内每个线程访问不同 bank,或者使用 “广播”(多个线程读同一地址不会冲突)(广播是什么?)
每个SM的 shared memory 只有几十 KB,一般是48KB,64kb,96KB等。使用过多会限制同时驻留的 block 数量
记得查一下什么是tile-based。
下面的代码很直观地展示了如何使用Shared Memory:
静态分配:
// 静态分配,编译期就确定大小
__global__ void kernel() {
__shared__ float buf[256]; // 大小在编译期已知
int tid = threadIdx.x;
buf[tid] = tid * 1.0f; // 所有线程读写同一片 shared memory
__syncthreads(); // 同步,确保所有线程读写完毕
// 使用 buf...
}动态分配:
// 动态分配
__global__ void kernel() {
extern __shared__ float buf[]; // 大小运行时由 kernel 调用方指定
int tid = threadIdx.x;
buf[tid] = tid;
__syncthreads();
}调用kernel时设定大小:
int sharedSize = 256 * sizeof(float);
kernel<<<grid, block, sharedSize>>>();Shared Memory同步问题
由于Shared Memory可以被并行访问,因此需要考虑线程同步的问题。cuda中可以使用__syncthreads()来进行同步,下图展示了__syncthreads()的作用:
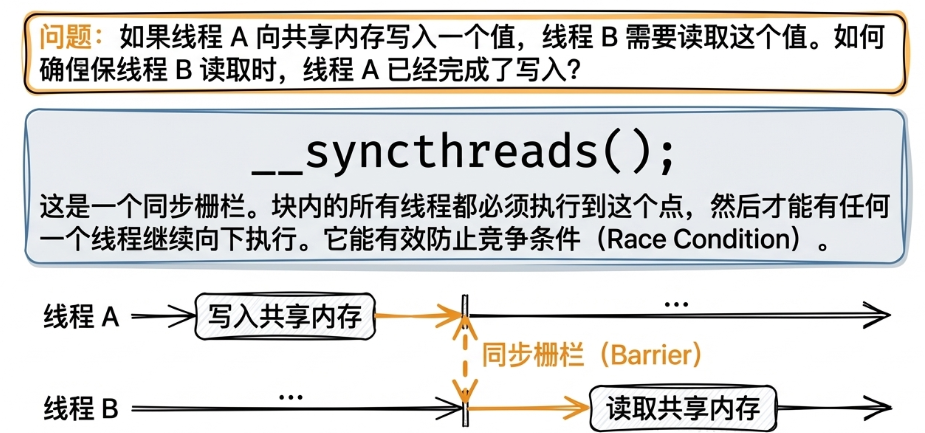
也就是说,它会让每个线程运行到这里时都停下来,直到所有线程都运行到此处,它才释放。同步每个线程的"进度"。
应用举例:向量点积并行计算
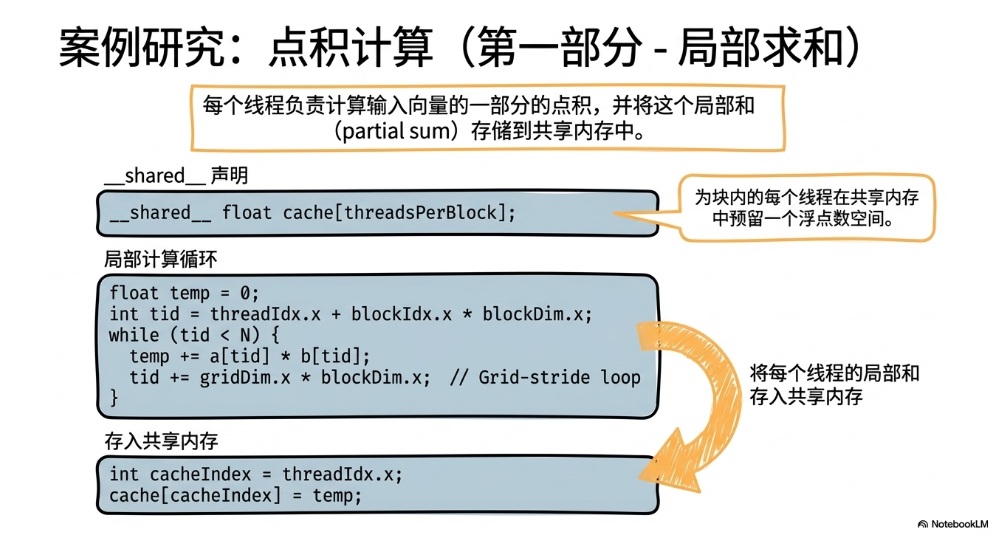
第一部分,首先将两个向量所有元素都对应相乘,每个线程负责一个索引,并将结果存入shared memory(也就是图中的cache)
这样一来,后面将每个乘法结果加起来的操作就能在shared memory(或者说在一个Block内)完成,不用总是访问global memory。
注意此处cache的大小被指定为threadsPerBlock,这是因为shared memory只能被一个block内的线程访问。所以下面的流程实际上只计算了threadsPerBlock个元素,最后需要把这些结果写回global memory,再在cpu上求和。
第二部分,将cache中的乘积结果加起来,得到最终的点积结果。也可以称之为并行归约。
首先需要使用__syncthreads()保证每一个元素的乘积结果都已经写入到cache中了;然后用下图所示的方法在原地进行求和计算,这里实际上只用到前面一半的线程,会抛弃掉后面一半。最终还需要再用一次__syncthreads() 保证全部求和操作都结束(因为后面还要写回global memory)。
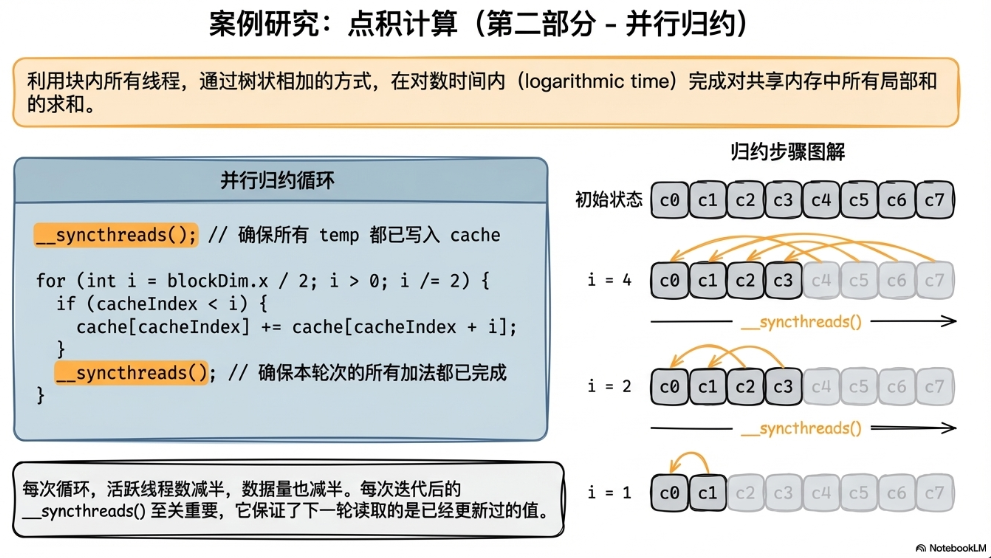
__syncthreads()的使用要注意:不管算法中是否需要用到所有线程,所有线程都必须执行到__syncthreads(),不然会死锁。比如上面的流程中,绝不能将__syncthreads()写到if里面。上面的例子还体现了一个思想:可以利用CPU做一些负担比较小,灵活性比较高的任务,比如最终的小规模求和。对于千万级别的向量点积,CPU在这里做的只是对block数量级别的数据求和。